

2024年7月号
生成AIの裾野を広げる安価な小規模言語モデル(SLM)

Open AIやマイクロソフト、グーグル、メタ等の巨大テック企業はAIに人間レベルのインテリジェンスを求めて、インターネット上の大量のデータを要する大規模言語モデル(LLM: Large Language Model)の開発に力を注いできた。これに対して、ここ数ヶ月、小さな言語モデル(SLM: Small Language Model)が注目を集めており、開発競争が激化している。SLMはしばしば用途を絞ることで、コンパクト化、効率化し、その領域では十分な受け答えができるように設計される。これまでLLMを推進してきたOpen AIのCEOのSam Altman氏も4月のイベントで、巨大モデルの時代は終焉を迎えていると確信している、と述べたという[i]。
[i] https://spectrum.ieee.org/small-language-models-apple-microsoft
大手しか手を出せないLLM開発
大手テック企業のSLM開発
Apple, Google, Microsoft等の大手やAI関連スタートアップは、LLMより安くて十分なパフォーマンスで顧客を獲得しようと、SLMの開発に取り組んでいる。
Apple 「Apple Intelligence」
Appleは6月のWorldwide Developers Conferenceで、Appleインテリジェンスを発表したが、そのモデルは30億パラメータ(機械学習モデルの内部変数の数)と小さい。対照的にLLMでは、例えば4月にMeta社が発表したLlama3は4千億ものパラメータを持つので、AppleのSLMは100分の1のサイズである。GPT-4のパラメータ数は非公開だが、一兆八千億円に及ぶと予測されている。
Appleは小規模モデルを使って、クラウドでなくiPhone上でAIを高速に安全に使えるようにする計画である。
Google「Gemma」
Googleは2月にGemmaと呼ばれるSLMを発表した。Gemmaは効率的でユーザーフレンドリーと謳われ、ラップトップ、スマホやタブレットで動作する。3月にはGemini Nanoを同社のスマートフォンPixelに導入した。
このSLMはクラウドに接続する必要はなく、スマホ上で録音した音声を要約し、返答を返すことができる。
Microsoft「Phi-3」
Microsoftは4月下旬にSLMのPhi-3を公開した。Phi-3ファミリーではGPT-3.5の100分の1のサイズ(38 億から 140 億のパラメーター数)の小型モデルを提供する。モデルは小さいがパフォーマンスも向上しており、Phi-3-small は、70 億という小規模パラメータに関わらず、言語、数学、コーディング等の分野で GPT-3.5 よりも優れたパフォーマンス結果を出している。
これはMicrosoftの研究者により開発された学習のイノベーションの結果で、インターネット上の大量のデータでなく、最初は高品質なデータを用意し慎重にモデルを訓練した。人間の教師が生徒に難しい概念を説明するように、教科書のような文章や、物事を適切に説明する極めて高品質な文章を使用し、学習を効率的にした。
Microsoftは、AIの利用動向において、あまり複雑ではないタスクを小型モデルに担わせる企業が出てくると予測している。Phi-3を使えば、長文の要約や市場調査レポートから業界動向を抽出したり、営業チームが商品説明やソーシャルメディアのコンテンツ作成、顧客サポートのチャットボットの作成などができる。
Microsoft生成 AI 担当プロダクトマネージャー主任のSonali Yadavは、「今後見られるようになるのは、大規模から小規模へのシフトではなく、モデルの単一カテゴリーからモデルのポートフォリオへのシフトです。お客様は自分のシナリオに最適なモデルを決定できるようになるでしょう」と述べている。多くの利用者が小さなモデルと大きなモデルを組み合わせて使うようになると同社は見ている。既にMicrosoft社内ではLLMが特定の質問をSLMへ誘導し、複雑な質問だけLLMが処理する、というモデルのポートフォリオを用いているという。
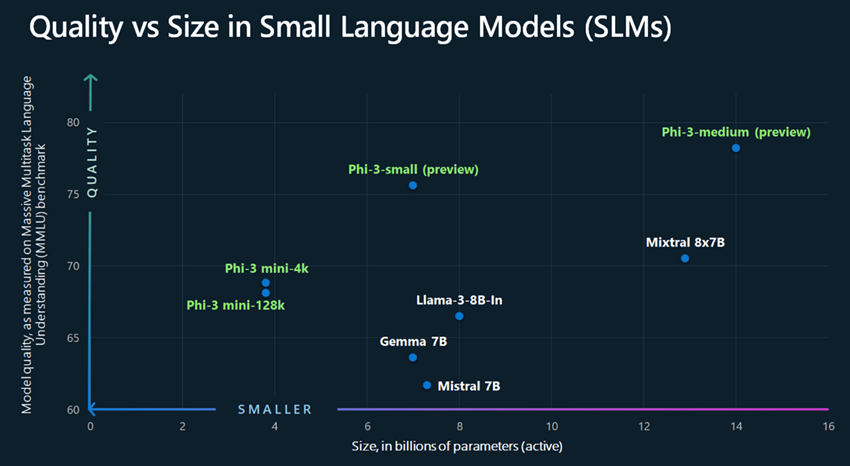
図1.Phi-3と他のモデルのサイズと質の比較 (ソース:Microsoft[i])
[i] https://news.microsoft.com/ja-jp/2024/04/24/240424-the-phi-3-small-language-models-with-big-potential/
スタートアップ企業のSLM開発
大手テック企業だけでなく、スタートアップもSLMに取り組んでいる。
Open AIの社員が創業したAnthropicやフランスのOpen AIのライバルであるMistral AIは今年に入って小規模言語モデルを発表した。AI向けデータ開発のスタートアップであるSnorkel AIは、企業がAIモデルをカスタマイズするのを支援するソリューションを提供している。データのラベル付けだけでなく、適切なモデル訓練用データのキュレーション、高品質データのフィルタリング、データの適切な組み合わせの選択、合成データによる補強など、実際に企業がモデルを自社用にカスタマイズ、調整するために細かく厳選されたデータセットを用意できるようにする。
AIのオープンソースプラットフォームのスタートアップのHuggingFace社は、開発者が機械学習モデルを構築、訓練、展開できるプラットフォームを提供しており、今年初めにGoogleとの戦略的提携を発表した。HuggingFaceをGoogleのVertex AIに統合し、開発者がGoogle VertexAIを通じて何千ものモデルを迅速に展開できるようにした。HuggingFaceのCEOであるClem Delangue氏は、最大99%のユースケースがSLMを使って対応できるとし、2024年はSLMの年になると予測している[i]。
[i] https://venturebeat.com/ai/why-small-language-models-are-the-next-big-thing-in-ai/
まとめ
大規模モデルは最近各社の機能の差が縮まっているが確実に進歩を続けており、小規模モデルがそのインテリジェンスのレベルに追いつくことはないと予想されている。ユーザーにとっては、LLM, SLMのそれぞれの長所、短所を理解して利用することが重要になる。AIのソリューション・プロバイダー、特にスタートアップにとっては、多大なコスト、リソースを必要としないSLM分野は大手に勝てる商機となる可能性もある。
(以上)
著者
川口 洋二氏
Delta Pacific Partners CEO。米国ベンチャーキャピタルの共同創業者兼ジェネラル・パートナー、日本と米国のクロスボーダーの事業開発を支援する会社の共同創業兼CEOなど、24年に渡るシリコンバレーでの経歴。NTT入社。スタンフォード大学ビジネススクールMBA。

DXの終焉と 新たな破壊サイクルAXの始まり
(アーカイブ配信)

LLMはそのサイズと処理能力により、深い知識の探索や広範囲な分野で力を発揮するが、訓練に莫大なデータが必要で、コンピューティングのパワーと電力を要するのが欠点である。
潤沢な開発費がかけられる大手以外はコアのLLMの開発に手が出せず、重要な技術基盤が大手数社に独占されてしまうリスクがある。Sam Altman氏はGPT-4の訓練のためのコストは少なくとも一億ドル(約155億円)が必要と述べている。
ところが、限られた用途では、この一般的な高コストのAIは必要ないかもしれない。さらに規模が大きく複雑なため、答えを得るのに待たされる、という不都合も生じる。また、LLMがなぜ間違った答えを返すのか、ブラックボックスで理由がわからないのも問題である。